 初识MySQL
初识MySQL
# 初识MySQL
# 1. bin目录下的可执行文件
- mysqld:
mysqld这个可执行文件就代表着MySQL服务器程序,运行这个可执行文件就可以直接启动一个服务器进程。但这个命令不常用,我们继续往下看更牛逼的启动命令。 - mysqld_safe:
mysqld_safe是一个启动脚本,它会间接的调用mysqld,而且还顺便启动了另外一个监控进程,这个监控进程在服务器进程挂了的时候,可以帮助重启它。另外,使用mysqld_safe启动服务器程序时,它会将服务器程序的出错信息和其他诊断信息重定向到某个文件中,产生出错日志,这样可以方便我们找出发生错误的原因。 - mysql.server:
mysql.server也是一个启动脚本,它会间接的调用mysqld_safe,在调用mysql.server时在后边指定start参数就可以启动服务器程序了。start参数换成stop就可以关闭正在运行的服务器程序。 - mysqld_multi:一台计算机上运行多个服务器实例,也就是运行多个
MySQL服务器进程。mysql_multi可执行文件可以对每一个服务器进程的启动或停止进行监控。
# 2. MySQL客户端
# 2.1. 登录MySQL服务器
在我们成功启动MySQL服务器程序后,就可以接着启动客户端程序来连接到这个服务器:
mysql -h主机名 -P端口 -u用户名 -p密码
- 像 h、u、p 这样名称只有一个英文字母的参数称为短形式的参数,使用时前边需要加单短划线。
- 像 host、user、password 这样大于一个英文字母的参数称为长形式的参数,使用时前边需要加双短划线。
退出MySQL命令行:quit ,exit,\q。
# 2.2. 客户端与服务器连接的过程
MySQL支持下边三种客户端进程和服务器进程的通信方式。
# TCP/IP
真实环境中,数据库服务器进程和客户端进程可能运行在不同的主机中,它们之间必须通过网络来进行通讯。MySQL采用TCP作为服务器和客户端之间的网络通信协议。在网络环境下,每台计算机都有一个唯一的IP地址,如果某个进程有需要采用TCP协议进行网络通信方面的需求,可以向操作系统申请一个端口号,这是一个整数值,它的取值范围是0~65535。这样在网络中的其他进程就可以通过IP地址 + 端口号的方式来与这个进程连接,这样进程之间就可以通过网络进行通信了。
# 命名管道和共享内存(Windows)
如果你是一个Windows用户,那么客户端进程和服务器进程之间可以考虑使用命名管道或共享内存进行通信。不过启用这些通信方式的时候需要在启动服务器程序和客户端程序时添加一些参数:
使用
命名管道来进行进程间通信:需要在启动服务器程序的命令中加上--enable-named-pipe参数,然后在启动客户端程序的命令中加入--pipe或者--protocol=pipe参数。使用
共享内存来进行进程间通信:需要在启动服务器程序的命令中加上--shared-memory参数,在成功启动服务器后,共享内存便成为本地客户端程序的默认连接方式,不过我们也可以在启动客户端程序的命令中加入--protocol=memory参数来显式的指定使用共享内存进行通信。需要注意的是,使用共享内存的方式进行通信的服务器进程和客户端进程必须在同一台Windows主机中。
# Unix域套接字文件
如果我们的服务器进程和客户端进程都运行在同一台操作系统为类Unix的机器上的话,我们可以使用Unix域套接字文件来进行进程间通信。如果我们在启动客户端程序的时候指定的主机名为localhost,或者指定了--protocal=socket的启动参数,那服务器程序和客户端程序之间就可以通过Unix域套接字文件来进行通信了。MySQL服务器程序默认监听的Unix域套接字文件路径为/tmp/mysql.sock,客户端程序也默认连接到这个Unix域套接字文件。如果我们想改变这个默认路径,可以在启动服务器程序时指定socket参数,就像这样:
mysqld --socket=/tmp/a.txt
这样服务器启动后便会监听/tmp/a.txt。在服务器改变了默认的UNIX域套接字文件后,如果客户端程序想通过UNIX域套接字文件进行通信的话,也需要显式的指定连接到的UNIX域套接字文件路径,就像这样:
mysql -hlocalhost -uroot --socket=/tmp/a.txt -p
这样该客户端进程和服务器进程就可以通过路径为/tmp/a.txt的Unix域套接字文件进行通信了。
# 3. 服务器处理客户端请求
其实不论客户端进程和服务器进程是采用哪种方式进行通信,最后实现的效果都是:客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。那服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?客户端可以向服务器发送增删改查各类请求,我们这里以比较复杂的查询请求为例来画个图展示一下大致的过程:
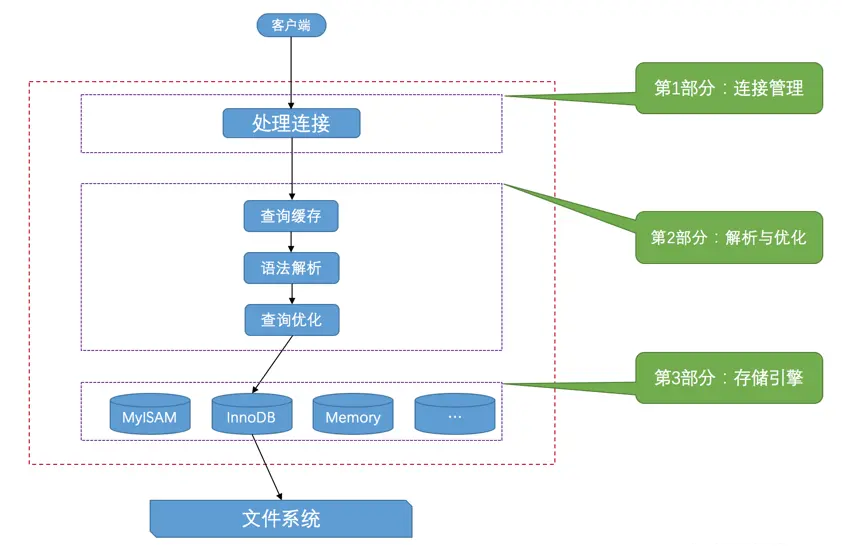
从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是连接管理、解析与优化、存储引擎。下边我们来详细看一下这三个部分都干了什么。
# 3.1. 连接管理
客户端进程可以采用我们上边介绍的TCP/IP、命名管道或共享内存、Unix域套接字这几种方式之一来与服务器进程建立连接,每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互,当该客户端退出时会与服务器断开连接,服务器并不会立即把与该客户端交互的线程销毁掉,而是把它缓存起来,在另一个新的客户端再进行连接时,把这个缓存的线程分配给该新客户端。这样就起到了不频繁创建和销毁线程的效果,从而节省开销。从这一点大家也能看出,MySQL服务器会为每一个连接进来的客户端分配一个线程,但是线程分配的太多了会严重影响系统性能,所以我们也需要限制一下可以同时连接到服务器的客户端数量,至于怎么限制我们后边再说哈~
在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证,如果认证失败,服务器程序会拒绝连接。另外,如果客户端程序和服务器程序不运行在一台计算机上,我们还可以采用使用了SSL(安全套接字)的网络连接进行通信,来保证数据传输的安全性。
当连接建立后,与该客户端关联的服务器线程会一直等待客户端发送过来的请求,MySQL服务器接收到的请求只是一个文本消息,该文本消息还要经过各种处理,预知后事如何,继续往下看哈~
# 3.2. 解析与优化
到现在为止,MySQL服务器已经获得了文本形式的请求,接着 还要经过九九八十一难的处理,其中的几个比较重要的部分分别是查询缓存、语法解析和查询优化,下边我们详细来看。
# 3.2.1. 查询缓存
从 MySQL 5.7.20开始,不推荐使用查询缓存,并在 MySQL 8.0中删除。
MySQL服务器程序处理查询请求的过程也是这样,会把刚刚处理过的查询请求和结果缓存起来,这个查询缓存可以在不同客户端之间共享如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql 、information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。
不过既然是缓存,那就有它缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT、 UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或 DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
# 3.2.2. 语法解析
MySQL服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上来。
# 3.2.3. 查询优化
MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接吧啦吧啦的一堆东西。优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是啥样的。我们可以使用EXPLAIN语句来查看某个语句的执行计划。
# 3.3. 存储引擎
截止到服务器程序完成了查询优化为止,还没有真正的去访问真实的数据表,MySQL服务器把数据的存储和提取操作都封装到了一个叫存储引擎的模块里。我们知道表是由一行一行的记录组成的,但这只是一个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎负责的事情。为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同存储引擎管理的表具体的存储结构可能不同,采用的存取算法也可能不同。
为了管理方便,人们把连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存储的功能划分为MySQL server的功能,把真实存取数据的功能划分为存储引擎的功能。各种不同的存储引擎向上边的MySQL server层提供统一的调用接口(也就是存储引擎API),包含了几十个底层函数,像"读取索引第一条内容"、"读取索引下一条内容"、"插入记录"等等。
所以在MySQL server完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的API,获取到数据后返回给客户端就好了。
# 4. 常用存储引擎
MySQL支持非常多种存储引擎,我这先列举一些:
| 存储引擎 | 描述 |
|---|---|
| ARCHIVE | 用于数据存档(行被插入后不能再修改) |
| BLACKHOLE | 丢弃写操作,读操作会返回空内容 |
| CSV | 在存储数据时,以逗号分隔各个数据项 |
| FEDERATED | 用来访问远程表 |
| InnoDB | 具备外键支持功能的事务存储引擎 |
| MEMORY | 置于内存的表 |
| MERGE | 用来管理多个MyISAM表构成的表集合 |
| MyISAM | 主要的非事务处理存储引擎 |
| NDB | MySQL集群专用存储引擎 |
最常用的就是InnoDB和MyISAM,有时会提一下Memory。其中InnoDB是MySQL默认的存储引擎,我们之后会详细唠叨这个存储引擎的各种功能,现在先看一下一些存储引擎对于某些功能的支持情况:
| Feature | MyISAM | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|
| B-tree indexes | yes | yes | yes | no | no |
| Backup/point-in-time recovery | yes | yes | yes | yes | yes |
| Cluster database support | no | no | no | no | yes |
| Clustered indexes | no | no | yes | no | no |
| Compressed data | yes | no | yes | yes | no |
| Data caches | no | N/A | yes | no | yes |
| Encrypted data | yes | yes | yes | yes | yes |
| Foreign key support | no | no | yes | no | yes |
| Full-text search indexes | yes | no | yes | no | no |
| Geospatial data type support | yes | no | yes | yes | yes |
| Geospatial indexing support | yes | no | yes | no | no |
| Hash indexes | no | yes | no | no | yes |
| Index caches | yes | N/A | yes | no | yes |
| Locking granularity | Table | Table | Row | Row | Row |
| MVCC | no | no | yes | no | no |
| Query cache support | yes | yes | yes | yes | yes |
| Replication support | yes | Limited | yes | yes | yes |
| Storage limits | 256TB | RAM | 64TB | None | 384EB |
| T-tree indexes | no | no | no | no | yes |
| Transactions | no | no | yes | no | yes |
| Update statistics for data dictionary | yes | yes | yes | yes | yes |
# 3.1. 查看当前服务器程序支持的存储引擎
SHOW ENGINES;
来看一下调用效果:
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.06 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- Support:表示该存储引擎是否可用
- DEFAULT:当前服务器程序的默认存储引擎。
- Comment:对存储引擎的一个描述。
- Transactions:该存储引擎是否支持事务处理。
- XA:该存储引擎是否支持分布式事务。
- Savepoints:该列是否支持部分事务回滚。
# 3.2. 设置表的存储引擎
我们前边说过,存储引擎是负责对表中的数据进行提取和写入工作的,我们可以为不同的表设置不同的存储引擎,也就是说不同的表可以有不同的物理存储结构,不同的提取和写入方式。
# 创建表时指定存储引擎
我们之前创建表的语句都没有指定表的存储引擎,那就会使用默认的存储引擎InnoDB。如果我们想显式的指定一下表的存储引擎,那可以这么写:
CREATE TABLE 表名(
建表语句;
) ENGINE = 存储引擎名称;
2
3
比如我们想创建一个存储引擎为MyISAM的表可以这么写:
CREATE TABLE engine_demo_table(
i int
) ENGINE = MyISAM;
2
3
# 修改表的存储引擎
如果表已经建好了,我们也可以使用下边这个语句来修改表的存储引擎:
ALTER TABLE 表名 ENGINE = 存储引擎名称;
比如我们修改一下engine_demo_table表的存储引擎:
ALTER TABLE engine_demo_table ENGINE = InnoDB;
这时我们再查看一下engine_demo_table的表结构:
mysql> SHOW CREATE TABLE engine_demo_table\G
*************************** 1. row ***************************
Table: engine_demo_table
Create Table: CREATE TABLE `engine_demo_table` (
`i` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.01 sec)
mysql>
2
3
4
5
6
7
8
可以看到该表的存储引擎已经改为InnoDB了。