 文本3剑客
文本3剑客
# grep
# 1.1 grep:文本过滤工具
grep命令是Linux系统中最重要的命令之—,其功能是从文本文件或管道数据流中筛选匹配的行及数据,如果再配和正则表达式的技术—起使用,则功能更加强大,它是Linux运维人员必须要掌握的命令之—!


基础示范:
grep -v "this" # 过滤不包括this的字符串
grep -n "this" # 过滤包含this的字符串,并显示行号
grep -i "this" # 不区分大小写,过滤包含this字符的行
grep -w "this" # 精准匹配包含this字符的行
2
3
4
过滤配置文件中的空白行:
利用正则表达式进行改名
^$|# 非$
grep -Ev "^$|#" nginx.conf
egrep -v "^$|#" nginx.conf
2
# 1.2 grep 正则表达式元字符和选项
| 元字符 | 功 能 | 示 例 | 示例的匹配对象 |
|---|---|---|---|
| ^ | 行首定位符 | /^love/ | 匹配所有以 love 开头的行 |
| $ | 行尾定位符 | /love$/ | 匹配所有以 love 结尾的行 |
| . | 匹配除换行外的单个字符 | /l..e/ | 匹配包含字符 l、后跟两个任意字符、再跟字母 e 的行 |
| * | 匹配零个或多个前导字符 | /*love/ | 匹配在零个或多个空格紧跟着模式 love 的行 |
| [] | 匹配指定字符组内任一字符 | /[Ll]ove/ | 匹配包含 love 和 Love 的行 |
| [^] | 匹配不在指定字符组内任一字符 | /[^A-KM-Z]ove/ | 匹配包含 ove,但 ove 之前的那个字符不在A 至K 或M 至Z 间的行 |
| \(..\) | 保存已匹配的字符 | ||
| & | 保存查找串以便在替换串中引用 | s/love/**&**/ | 符号&代表查找串。字符串 love将替换前后各加了两个**的引用,即 love 变成**love** |
| < | 词首定位符 | /<love/ | 匹配包含以 love 开头的单词的行 |
| > | 词尾定位符 | /love>/ | 匹配包含以 love 结尾的单词的行 |
| x{m} | 连续 m 个 x | /o{5}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
| x{m,} | 至少 m 个 x | /o{5,}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
| x{m,n} | 至少 m 个 x,但不超过 n 个 x | /o{5,10}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
# 1.3 egrep正则表达式元字符
| 元字符 | 功 能 | 示 例 | 示例的匹配对象 |
|---|---|---|---|
| ^ | 行首定位符 | /^love/ | 匹配所有以 love 开头的行 |
| $ | 行尾定位符 | /love$/ | 匹配所有以 love 结尾的行 |
| . | 匹配除换行外的单个字符 | /l..e/ | 匹配包含字符 l、后跟两个任意字符、再跟字母e 的行 |
| * | 匹配零个或多个前导字符 | /*love/ | 匹配在零个或多个空格紧跟着模式 love 的行 |
| [] | 匹配指定字符组内任一字符 | /[Ll]ove/ | 匹配包含 love 和 Love 的行 |
| [^] | 匹配不在指定字符组内任一字符 | /[^A-KM-Z]ove/ | 匹配包含 ove,但 ove 之前的那个字符不在A 至K 或M 至Z间的行 |
| + | 匹配一个或多个多个加号前面的字符 | [a-z]+ove' | 匹配一个或多个小写字母后跟 ove 的字符串。 move love approve |
| ? | 匹配0个或一个前导字符 | lo?ve' | 匹配l 后跟一个或 0 个字母 o以及 ve 的字符串。 love lve |
| a | b | 匹配 a 或 b | 'love |
| () | 字符组 | 'love(able | ly)(ov+)' |
# 1.4 grep实践
# sed
# 2.1 sed :字符流编辑器
sed是操作、过滤和转换文本内容的强大工具。常用功能包括对文件实现快速增删改查(增加、删除、修改、查询),其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。
# 2.1.1 sed参数
| 选项 | 说明 |
|---|---|
| -n | 使用安静模式,在一般情况所有的 STDIN 都会输出到屏幕上,加入-n 后只打印被 sed 特殊处理的行 |
| -e | 多重编辑,且命令顺序会影响结果 |
| -f | 指定一个 sed 脚本文件到命令行执行, |
| -r | Sed 使用扩展正则 |
| -i | 直接修改文档读取的内容,不在屏幕上输出 |
# 2.1.2 sed命令
| 命令 | 说明 |
|---|---|
| a\ | 在当前行后添加一行或多行 |
| c\ | 用新文本修改(替换)当前行中的文本 |
| d | 删除行 |
| i\ | 在当前行之前插入文本 |
| h | 把模式空间里的内容复制到暂存缓存区 |
| H | 把模式空间里的内容追加到暂存缓存区 |
| g | 取出暂存缓冲区里的内容,将其复制到模式空间,覆盖该处原有内容 |
| G | 取出暂存缓冲区里的内容,将其复制到模式空间,追加在原有内容后面 |
| l | 列出非打印字符 |
| p | 打印行 |
| n | 读入下一输入行,并从下一条命令而不是第一条命令开始处理 |
| q | 结束或退出 sed |
| r | 从文件中读取输入行 |
| ! | 对所选行意外的所有行应用命令 |
| s | 用一个字符串替换另一个 |
# 2.1.3 sed正则表达式
| 元字符 | 功 能 | 示 例 | 示例的匹配对象 |
|---|---|---|---|
| ^ | 行首定位符 | /^love/ | 匹配所有以 love 开头的行 |
| $ | 行尾定位符 | /love$/ | 匹配所有以 love 结尾的行 |
| . | 匹配除换行外的单个字符 | /l..e/ | 匹配包含字符 l、后跟两个任意字符、再跟字母 e 的行 |
| * | 匹配零个或多个前导字符 | /*love/ | 匹配在零个或多个空格紧跟着模式 love 的行 |
| [] | 匹配指定字符组内任一字符 | /[Ll]ove/ | 匹配包含 love 和 Love 的行 |
| [^] | 匹配不在指定字符组内任一字符 | /[^A-KM-Z]ove/ | 匹配包含 ove,但 ove 之前的那个字符不在A 至K 或M 至Z 间的行 |
| \(..\) | 保存已匹配的字符 | ||
| & | 保存查找串以便在替换串中引用 | s/love/**&**/ | 符号&代表查找串。字符串 love将替换前后各加了两个**的引用,即 love 变成**love** |
| < | 词首定位符 | /<love/ | 匹配包含以 love 开头的单词的行 |
| > | 词尾定位符 | /love>/ | 匹配包含以 love 结尾的单词的行 |
| x{m} | 连续 m 个 x | /o{5}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
| x{m,} | 至少 m 个 x | /o{5,}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
| x{m,n} | 至少 m 个 x,但不超过 n 个 x | /o{5,10}/ | 分别匹配出现连续 5 个字母 o、至少 5 个连续的 o、或 5~10 个连续的 o 的行 |
sed 把当前正在处理的行保存在一个临时缓存区中,这个缓存区称为模式空间或临时缓冲。 sed 处理完模式空间中的行后(即在该行上执行 sed 命令后),就把该行发送到屏幕上(除非之前有命令删除这一行或取消打印操作)。 sed 每处理完输入文件的最后一行后, sed 便结束运行。 sed 把每一行都存在临时缓存区中,对这个副本进行编辑,所以不会修改或破坏源文件。

# 2.2 sed命令格式
Sed 支持一下几种地址类型:
- first~step:first 指起始匹配行,step 指步长,例如
sed -n 2~5p含义:从第二行开始匹配,隔 5 行匹配一次,即 2,7,12....... - $ 匹配最后一行。
- /REGEXP/ 匹配正则那一行,通过 // 之间的正则来匹配;
- \cREGEXPc 这个是表示匹配正则那一行,通过 \c 和 c 之间的正则来匹配 ,c 可以是任一字符。
- addr1,add2 形式可以是数字、正则表达式或二者的结合。如果没有指定地址,sed将处理输入文件中的所有行。 如果地址是一个数字,则这个数字代表行号,如果是逗号分隔的两个行号,那么需要处理的地址就是两行之间的内容(包括两行在内)。
# 2.3 sed演示示例
# 2.3.1 打印:p
p是打印命令,用于显示缓存区的内容。默认情况下,sed会把所有行打印在命令行中,-n 用于只打印被sed处理的行数。-n 与 p 同时出现时,sed将打印选定的内容。
[root@vmware_docker /tmp/Linux/test]# sed -n '1,5p' sed_test # 打印前5行的内容
# $OpenBSD: sshd_config,v 1.103 2018/04/09 20:41:22 tj Exp $
# This is the sshd server system-wide configuration file. See
# sshd_config(5) for more information.
2
3
4
5
root@vmware_docker /tmp/Linux/test]# sed -n '/1/p' sed_test # 查找文件中带 1 的行并打印出来
# $OpenBSD: sshd_config,v 1.103 2018/04/09 20:41:22 tj Exp $
HostKey /etc/ssh/ssh_host_ed25519_key
#MaxSessions 10
X11Forwarding yes
#X11DisplayOffset 10
#X11UseLocalhost yes
#MaxStartups 10:30:100
# X11Forwarding no
2
3
4
5
6
7
8
9
# 2.3.2 删除:d
d用于删除输入行。sed先将输入行从文件复制到模式缓存区,然后对该行执行sed命令,最后将缓存区的内容显示在屏幕上。
[root@vmware_docker /tmp/Linux/test]# sed '2d' sed_test # 删除第二行,并打印其他行
......
2
# 2.3.3 替换:s
s是替换命令。s后面包含在斜杠中的文本是正则表达式,后面跟着的是需要替换的文本。可以通过 g 标志对行进行全局替换。
[root@vmware_docker /tmp/Linux/test]# sed -n 's/1/2/gp' sed_test # 把行中所有 1 替换为 2 ,并打印出受影响的行
# $OpenBSD: sshd_config,v 2.203 2028/04/09 20:42:22 tj Exp $
HostKey /etc/ssh/ssh_host_ed25529_key
#MaxSessions 20
X22Forwarding yes
#X22DisplayOffset 20
#X22UseLocalhost yes
#MaxStartups 20:30:200
# X22Forwarding no
2
3
4
5
6
7
8
9
如果没有 g 命令,则只将每一行的第一个单词替换
[root@vmware_docker ~/test]# sed -n 's/1/2/p' sed_test
# $OpenBSD: sshd_config,v 2.103 2018/04/09 20:41:22 tj Exp $
212121212121
212121212121
,223456789
HostKey /etc/ssh/ssh_host_ed25529_key
#MaxSessions 20
X21Forwarding yes
#X21DisplayOffset 10
#X21UseLocalhost yes
#MaxStartups 20:30:100
# X21Forwarding no
2
3
4
5
6
7
8
9
10
11
12
# 2.3.4 指定行的范围:逗号
形式可以是数字、正则表达式或二者的结合。如果没有指定地址,sed将处理输入文件中的所有行。 如果地址是一个数字,则这个数字代表行号,如果是逗号分隔的两个行号,那么需要处理的地址就是两行之间的内容(包括两行在内)。如果结束条件无法满足,就会一直操作到文件结尾。如果结束条件满足,则继续查找满足开始条件的位置,范围重新开始。
需填写
# 2.3.5 行后插入:a | 行前插入:i
[root@vmware_docker /etc/nginx]# sed '2ised2i' nginx.conf
# For more information on configuration, see:
sed2i
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
2
3
4
5
[root@vmware_docker /etc/nginx]# sed '2ased2a' nginx.conf
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
sed2a
# * Official Russian Documentation: http://nginx.org/ru/docs/
2
3
4
5
# 2.4 sed实战
# 2.4.1 取出本机ip地址
[root@vmware_docker /etc/nginx]# ifconfig -a | grep flags -A1 | grep ens33 -A1 | grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"
192.168.7.2
2
# awk
# 3.1 awk
awk 是一种很棒的语言,它适合文本处理和报表生成 ,处理的数据可以是—个或多个文件,它是Linux系统最强大的文本处理工具,没有之—。
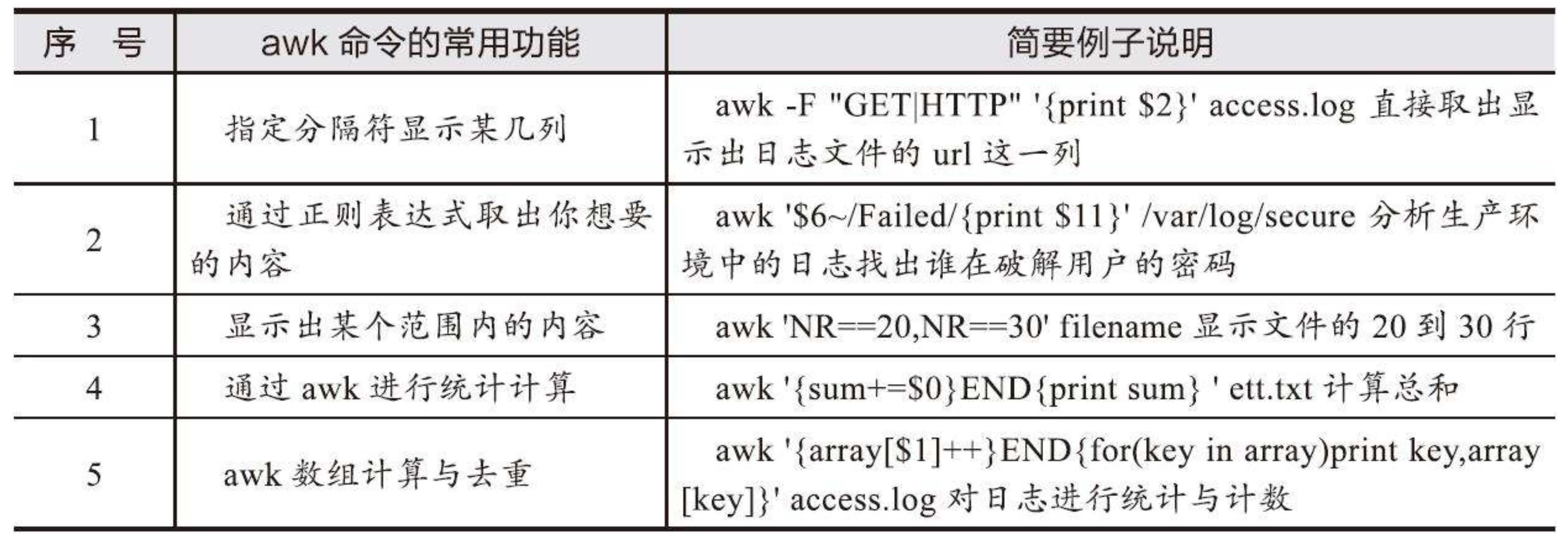


# 3.2 awk详解实战
# 3.2.1 常用awk内置变量
| 变量名 | 属性 |
|---|---|
| $0 | 当前记录 |
| $1~$n | 当前记录的第n个字段 |
| FS | 输入字段分隔符,默认是空格 |
| RS | 输入记录分割符,默认为换行符 |
| NF | 当前记录中的字段个数,就是有多少列 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFS | 输出字段分隔符默认也是空格 |
| ORS | 输出的记录分隔符默认为换行符 |
- NR在awk 中表示行号(记录号), NR==5表示行号等于5的行
# 3.2.2 awk实战
使用awk显示从第二行到第六行的内容
[root@vmware_docker ~/test]# awk 'NR==2,NR==6' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
2
3
4
5
6
使用awk命令达到与cat -n相同的结果
[root@vmware_docker ~/test]# awk '{print NR,$0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
...
2
3
4
5
6
7
8
9
10
11
12
awk中,$0表示一整行的内容(一行的内容),所以
awk '{print NR,$0}'中,NR是显示行号,$0显示一整行内容,所以才可以做到跟cat -n是一样的输出
使用awk命令,显示 /etc/passwd 的2-6行,并打印行号
[root@vmware_docker ~]# awk 'NR==2,NR==6{print NR,$0}' /etc/passwd
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
2
3
4
5
6
使用awk命令,显示 第一列,三列,最后一列,以 ':' 作为分隔符
[root@vmware_docker ~]# awk -F ":" '{print $1,$3,$NF}' /etc/passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
...
2
3
4
5
6
7
8
9
10
11
12
